
Flask中使用flask-httpauth实现HTTP协议的token验证
Flask中通常使用Flask-login进行登录验证,而Flask-login使用的是Session实现的登录状态验证,这样就导致每次重新打开网页的时候需要重复登录,或者当出现分布式的时候由于其他服务器可能未与客户端建立连接无法获取登录状...
Flask中通常使用Flask-login进行登录验证,而Flask-login使用的是Session实现的登录状态验证,这样就导致每次重新打开网页的时候需要重复登录,或者当出现分布式的时候由于其他服务器可能未与客户端建立连接无法获取登录状...

Blinker是为了Python提供简单快速的信号机制,其核心就是框架核心功能或者是Flask扩展发生动作时所发送的通知,用于解耦大型应用功能。
常见的Flask Web开发教程大多都是使用sqlite数据库作为开发存储数据库,本篇文章主要介绍如何在Flask中使用mysql数据库。
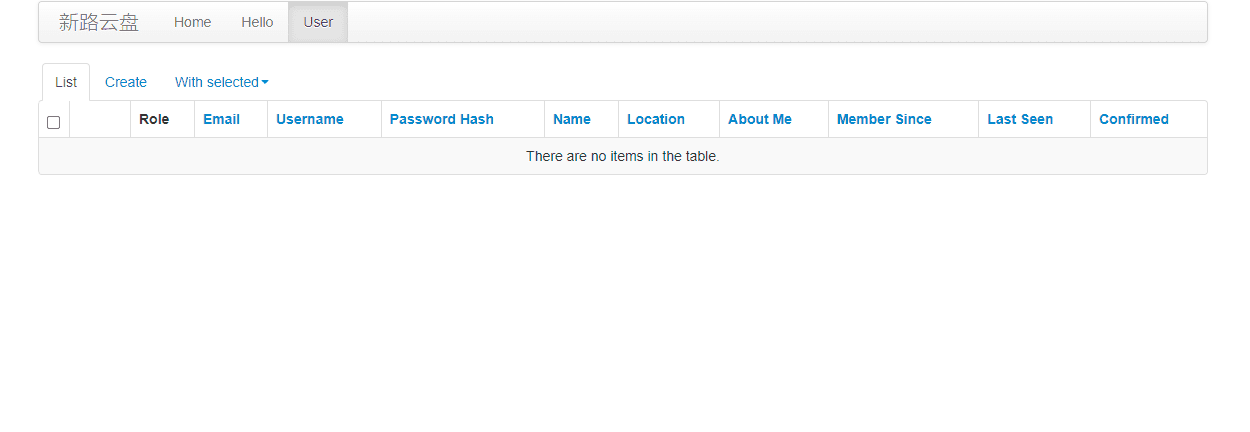
Flask中提供了flask-admin用来解决在现有数据模型之上构建管理界面的问题。我们只需要写很少的代码,它就可以通过友好的界面来管理web服务的数据。
Python 是一种易于学习又功能强大的编程语言。它提供了高效的高级数据结构,还能简单有效地面向对象编程。Python 优雅的语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的理想语言。
Flask提供了很多有用的扩展程序,我们可以通过使用flask-script扩展来实现软件的运行、配置数据库、以及自定义shell命令的目的。
排查flask-script源码可以发现 flask._compat不存在,flask中不存在该模块,出现这种问题无外乎是由于两种情况导致的:flask版本不适配flask-script版本、flask-script版本不支持当前flask...

Flask是Python中目前比较流行的一款Web框架,Flask小巧精简,且便于扩展。Flask内置Jinja2模板引擎模块实现前端模板语言渲染。本篇文章主要给出Flask开发学习指南。

蓝图(Blueprint)是Flask实现的应用模块化,通过模块化的方式分割视图,让应用的层次更加清晰,更加便于开发者开发和维护项目。通过蓝图,我们可以创建一组相同前缀的路由组合,可以用于分割应用不同的服务。如应用有两个服务:认证服务和用户...

使用Flask可以直接在路由中返回Html文档,但处理起来比较麻烦。因此,Flask框架默认支持Jinja2末班引擎,可通过flask提供的内置方法render_template直接进行渲染,我们只需要提供html的相对路径即可,flask...

更多前端知识请关注:"胖蔡话前端"
