
计算机系统中的数据表示方法
各种数值在计算机中表示的方法称之为机器数,其特点是采用二进制,即使用数据0和1表示,小数点则隐含(不占位置)。机器数对应的实际数值称之为真值。
各种数值在计算机中表示的方法称之为机器数,其特点是采用二进制,即使用数据0和1表示,小数点则隐含(不占位置)。机器数对应的实际数值称之为真值。
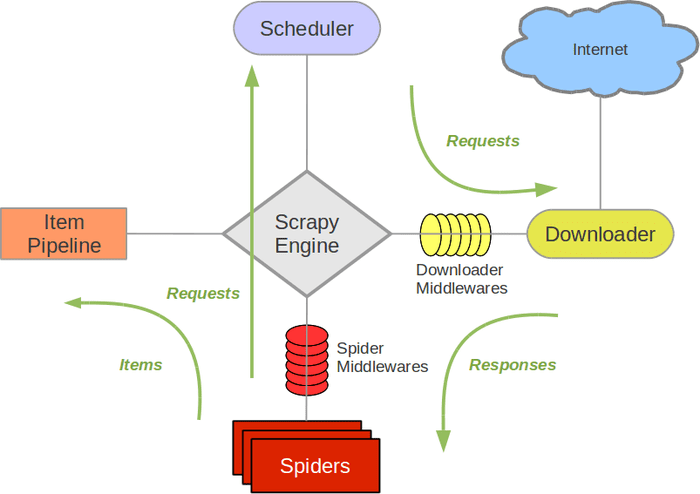
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。

Tesseract 是一个 OCR 库,目前由 Google 赞助(Google 也是一家以 OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源 OCR 系统。 除了极高的精确度,Tesseract ...
计算机系统运行时,系统为确保数据在传输过程中不出错,一般会通过:提高硬件电路的可靠性和提高代码的校验能力(差错和纠错)实现数据传输的稳定性。
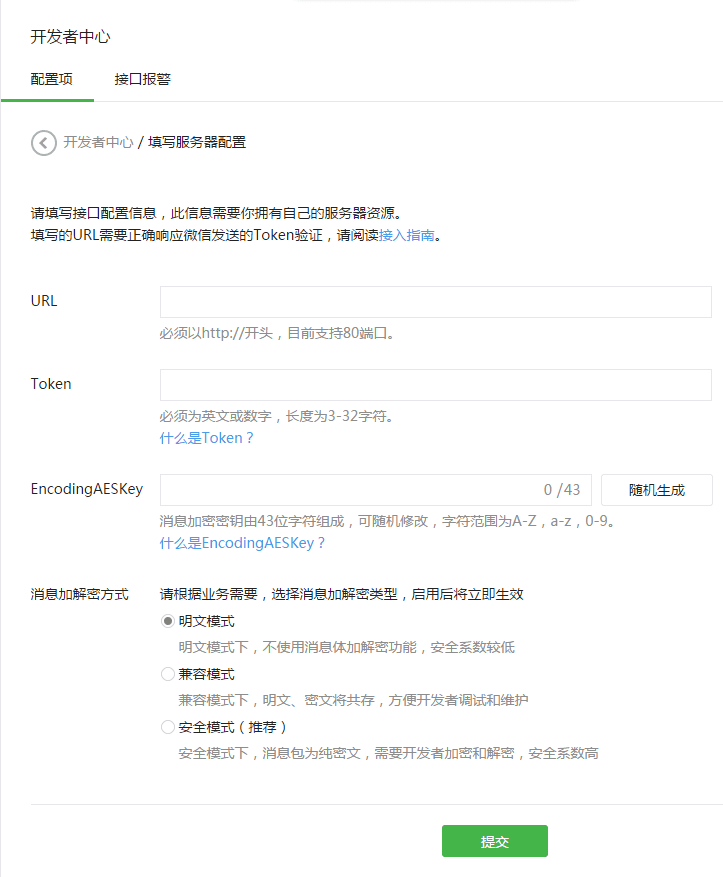
登录微信公众平台官网后,在公众平台后台管理页面 - 开发者中心页,点击“修改配置”按钮,填写服务器地址(URL)、Token和EncodingAESKey,其中URL是开发者用来接收微信消息和事件的接口URL。Token可由开发者可以任意填...

一种更复杂的链表是“双向链表”或“双面链表”。每个节点有两个链接:一个指向前一个节点,当此节点为第一个节点时,指向空值;而另一个指向下一个节点,当此节点为最后一个节点时,指向空值。

和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
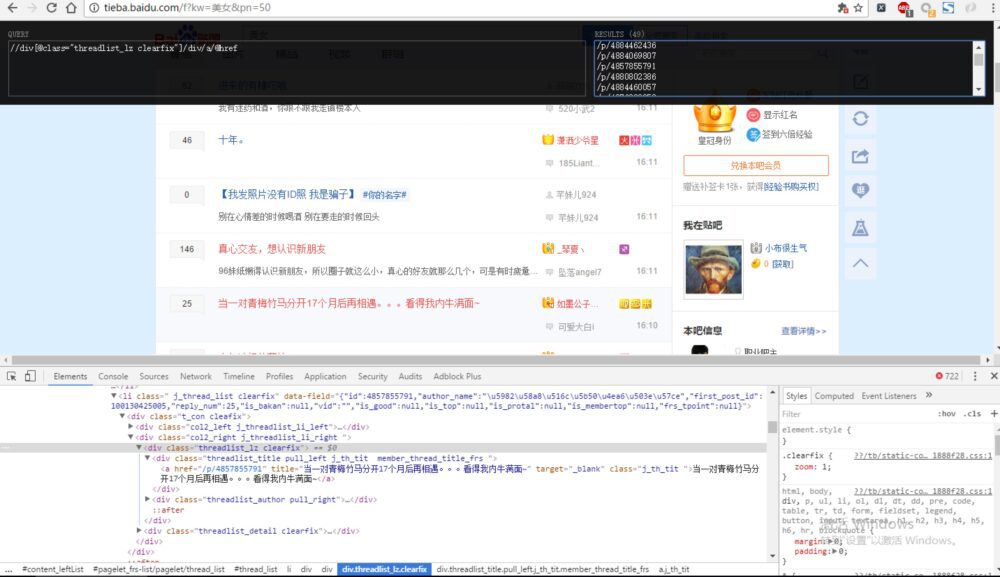
XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层发布的图片下载到本地。

Requests 继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。Requests能完全...
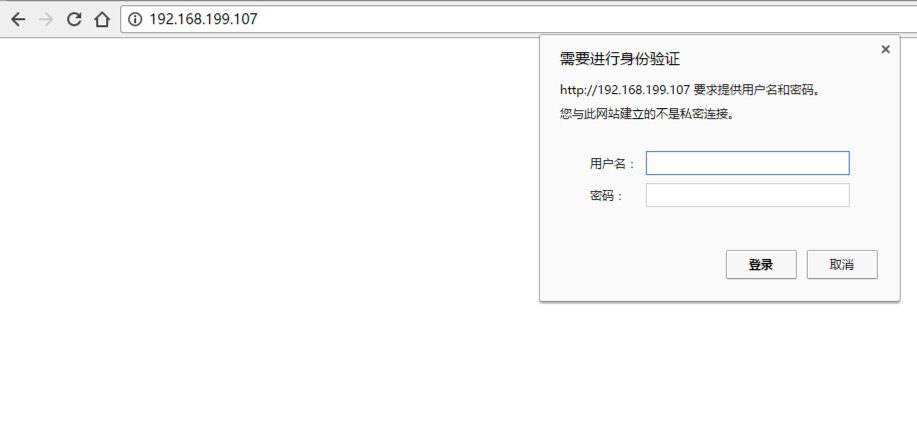
opener是 urllib2.OpenerDirector 的实例,我们之前一直都在使用的urlopen,它是一个特殊的opener(也就是模块帮我们构建好的)。

更多前端知识请关注:"胖蔡话前端"
